Baseline Model
How well can we predict exchange rates considering only past values?
In building a baseline model we considered several approaches including univariate versions of ARIMA models (autoregreesive integrated moving average models involving using lagged values of the response variable as well as moving average terms), and autoregressive models as well as multivariate models incorporating Libor rates and lastly sentiment scores.
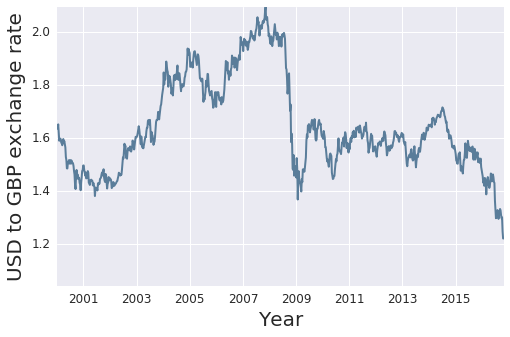
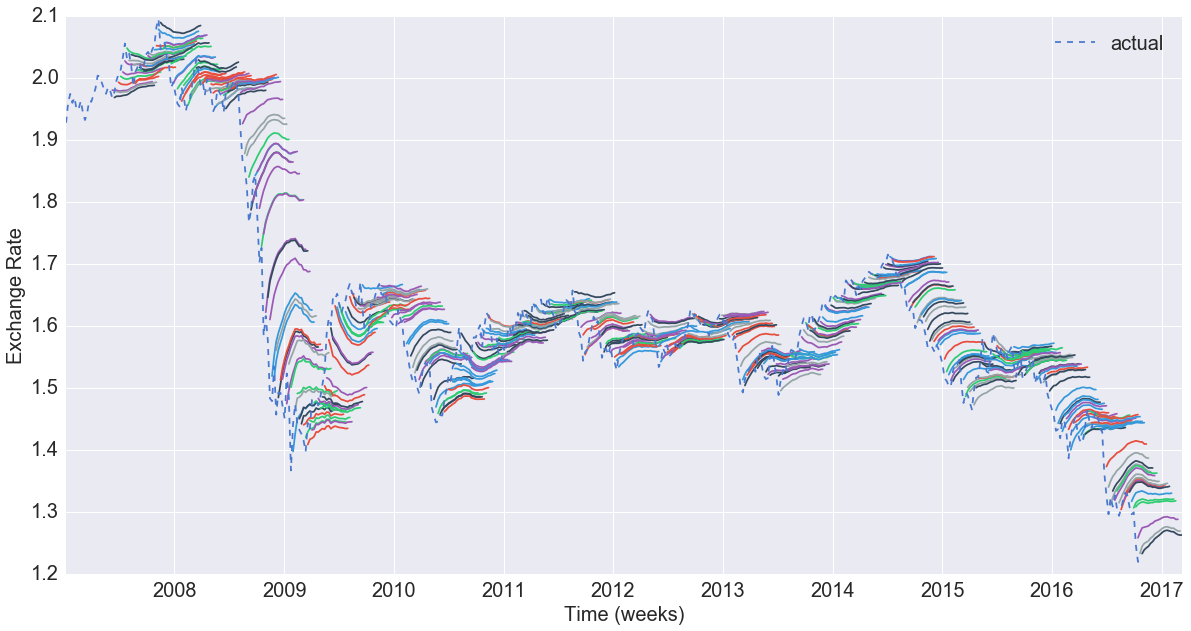
Exchange Rate Series
Let's take a look again at the exchange rate plot, zooming in on times of interest
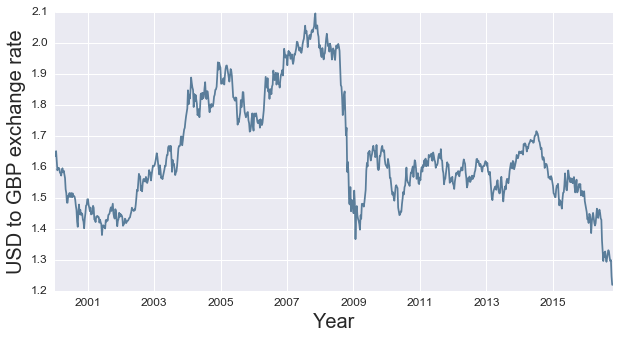
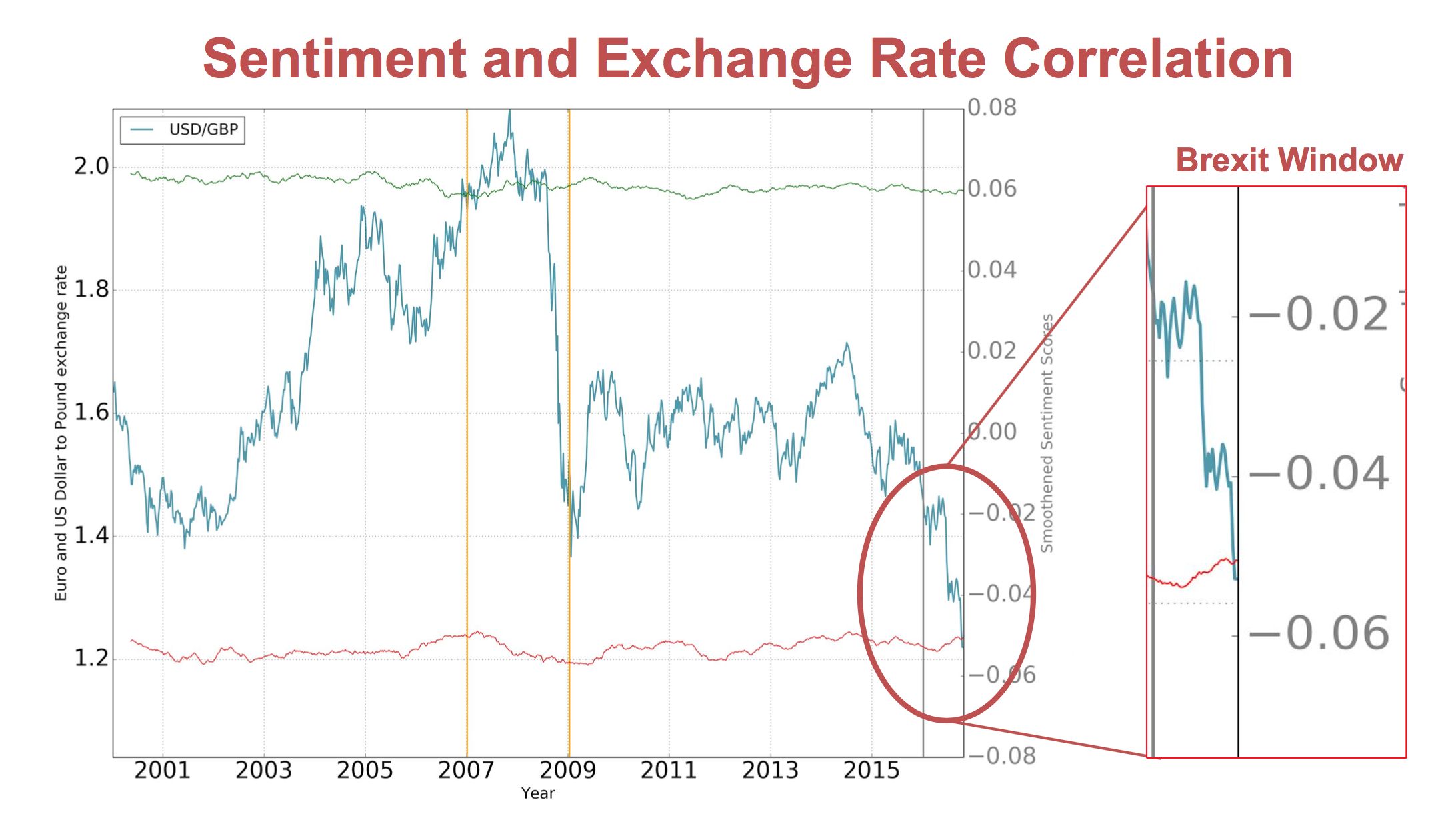
First, lets take a look at the global financial crisis, and event that preciptated a drastic change in the UK-US exchange rate.
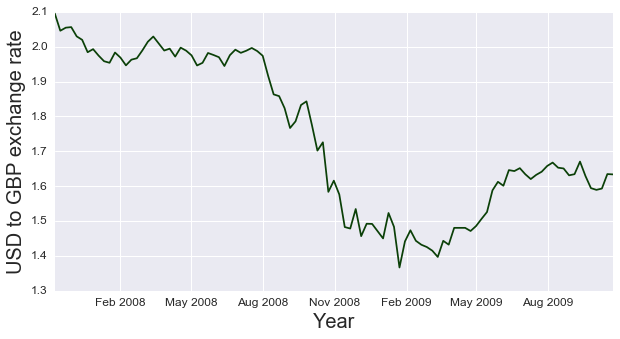
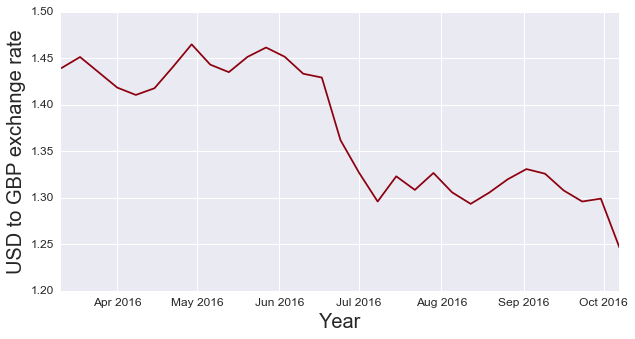
Next, take a look at the at the time period around the Brexit referendum, which saw the value of the GBP at a local minimum relative to a 25 year time horizon.
Stationarity
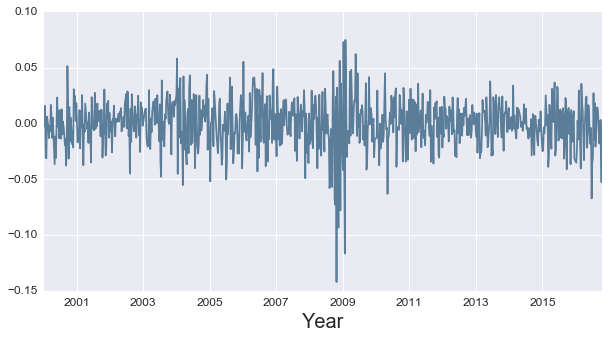
An important assumption in much of models underlying time series analysis is that the mean and variance of the data do not change over time; if the data has an underlying trend, this will certainly not be true. As such, most time series analysis occurs on data rendered stationary, traditionally by taking first differences. After differencing, we see that aside from a time of extreme variation around the global financial crisis, data is reasonably stationary with mean zero and relatively stable variance outside of the 2008-2010 time frame. Keeping the anomalies of the financial crisis in mind, we can move on to the next segment in building our model.
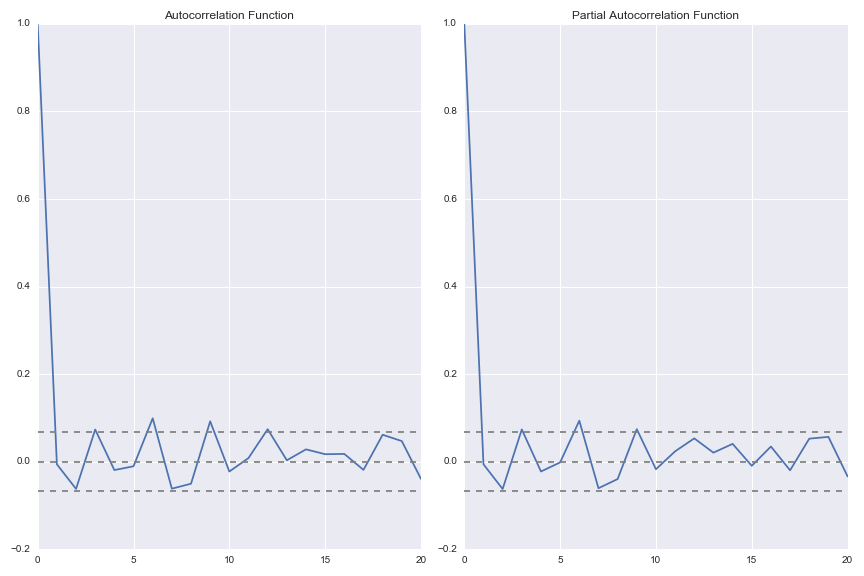
Autocorrelation
Let's first start by taking a deeper dive into the first lag of the first-differenced
exchange rate as this should give us some information as to whether or not a simple
AR(1) process can adequately model our data. If we see a non-zero slope in the correlation plot,
we can infer that there is, in fact, a good relationship between this week's exchange rate and last week's exchange rate.
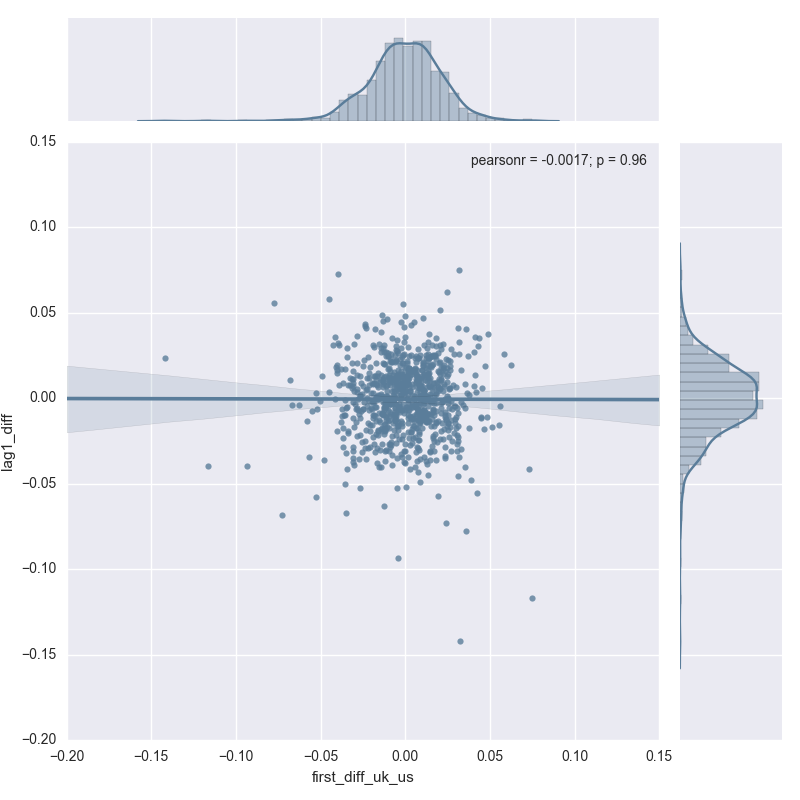
The first difference is almost certainly zero, with both axes having data appearing to be drawn
from a roughly normal distribution with mean zero. There does not appear to be much gleaned from relying entirely on the first lag.
Let's now take a look at further lags (lags 2 through 40) to see if there is any other information available in prior lags.
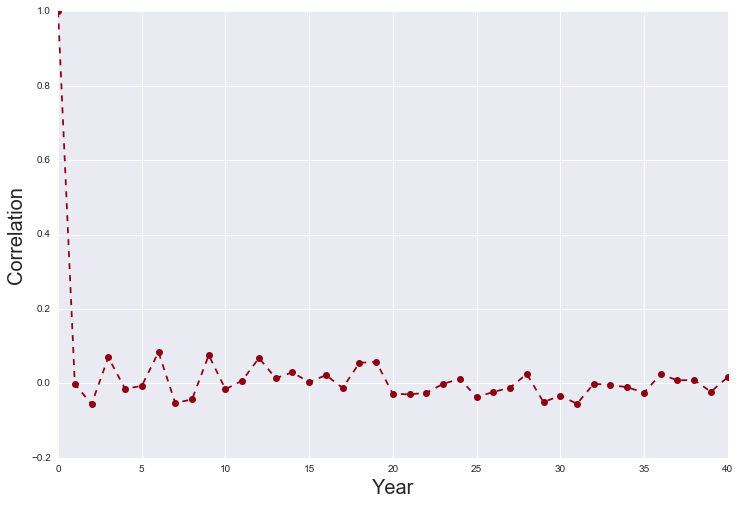
The lags appear to bounce around zero - an AR process might not be able to glean all that
much from the underlying data, although regularization might improve this (discussed later)
Univariate ARMA models
Although we saw from the autocorrelation plot above that an AR processes will likely perform trivially, a well-developed baseline model is required against which we will compare our sentiment score-augmented model.
ARIMA models are set of time series methods that include autoregressive components (AR), differencing (I), and moving average terms (MA) in order to capture various dimensions by which time series trends can be described.
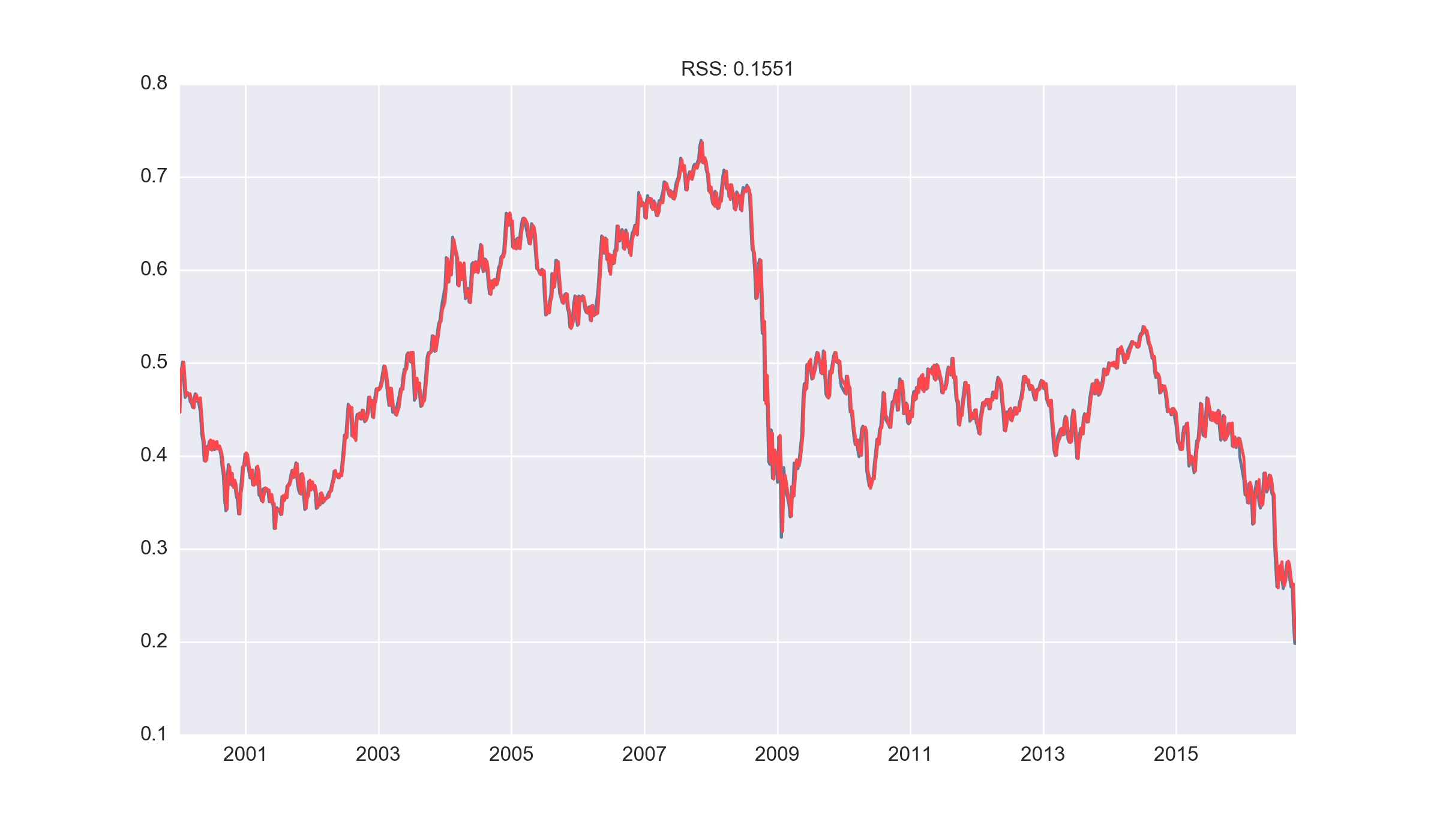
AR model
As mentioned earlier, AR terms capture the number of lags to be used by the model. Here, we select an AR(6) process as the sixth lag is somewhat significant in both the ACF and PACF plots above. The AR(6) process appears to perform quite well (although we should remember that exchange rates do not vary all too much week over week).
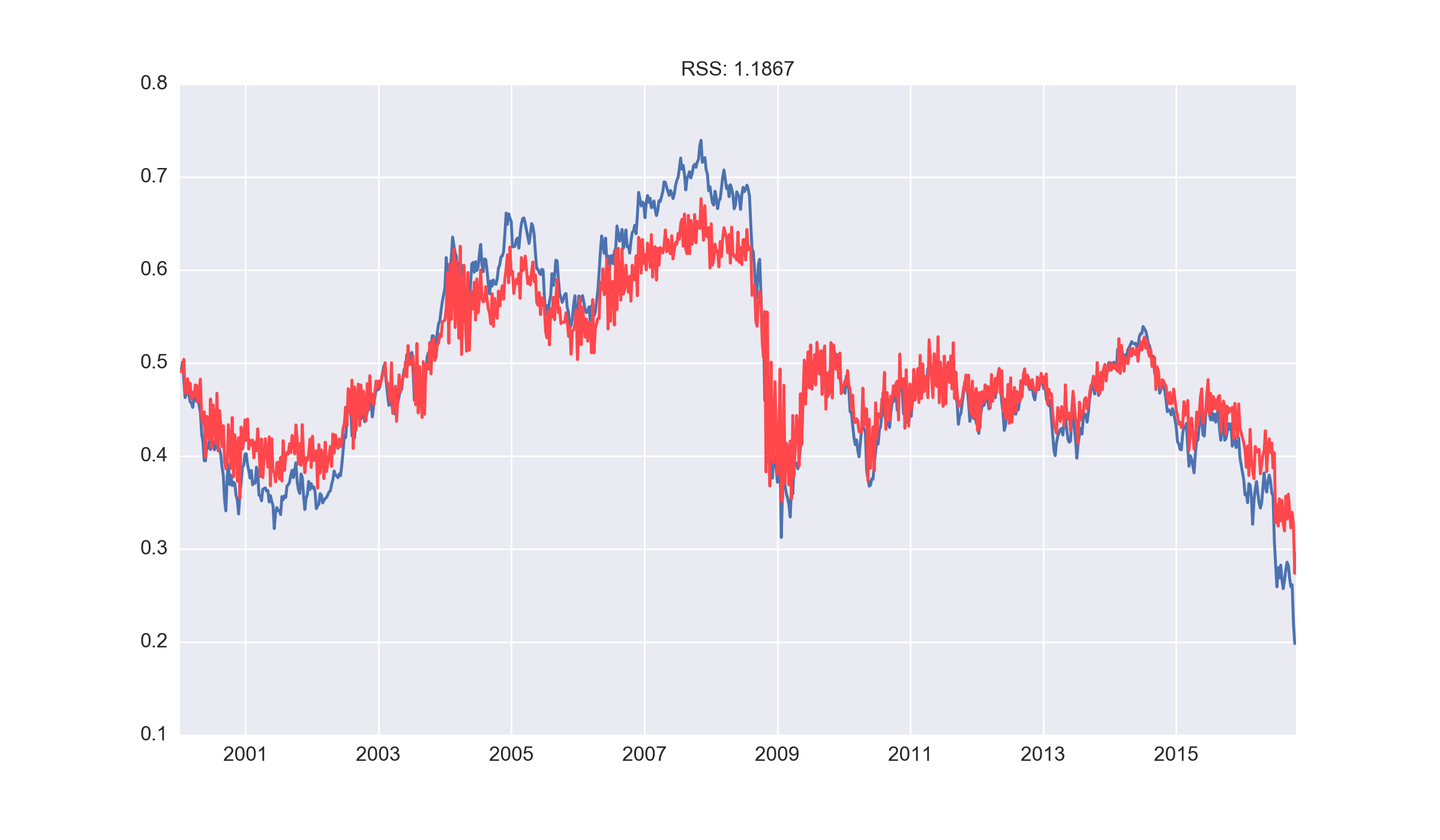
MA model
We also considered a standalone moving average model (using two moving average terms) for the sake of exploration. This appeared to attenuate the magnitude of our predictions and lead to a poor model result.
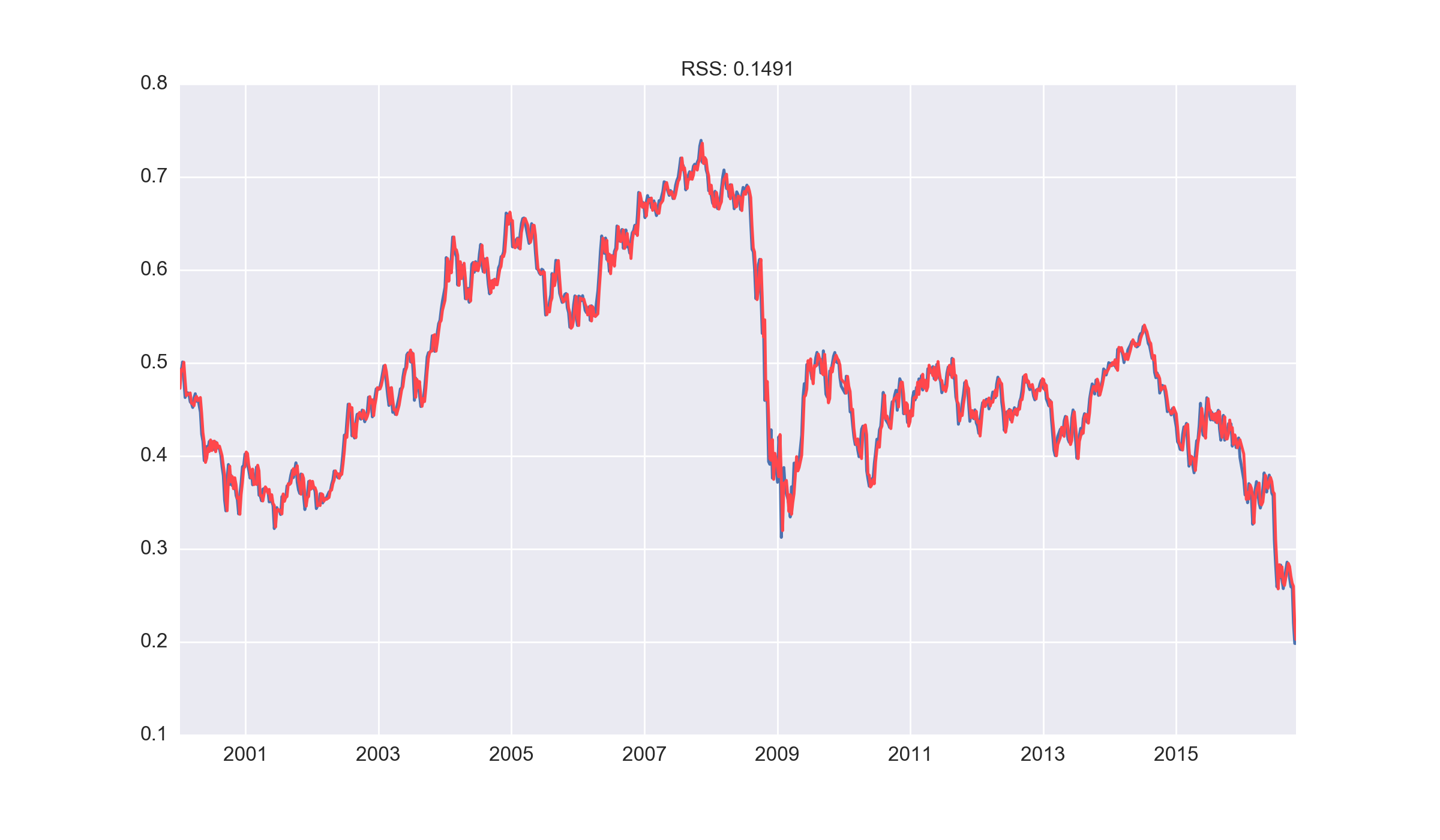
ARMA model
Our final baseline model was a combined ARMA (6,5) process that yielded the lowest RSS on the data, with a plot of the prediction overlayed on the original data below.
Lasso regression model
For further improvements from the baseline model, several other models were considered including regression models with L1 and L2 regularisation. This is equivalent to an autoregressive model and would enable us to examine the magnitude of the coefficients assigned to each lag (i.e. the importance of each lag in generating a prediction).
1. Create a matrix of lagged predictors
Matrices of predictors were generated with the lagged response variable and this was used with Lasso regression to determine the coefficients of the lags. The data was of the form:
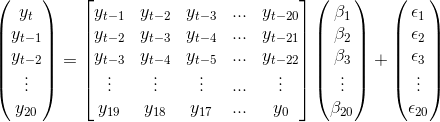
To determine the number of lags used in our model, we split the given data into training and test sets and analysed the cross validation scores. This is gave 20 lags as being the optimal choice, as shown in the matrix above.
2. Split into test and train sets and analyse model forecasts
As the predictors are given by the rows of the predictor matrix, each observation is independent i.e. sequential slices of the data are no longer required for cross validation. The data was randomly split into test (40%) and train (60%) sets
3. Use lasso regression to fit a model to the training data
Having chosen the number of lags, we now fit a lasso regression model on the training data. We choose to use the lasso because it would give sparse coefficients in our prediction lag variables, so that potential interpretations can be made after the fit. Cross validated Lasso regression was used to optimise the hyperparameters.
4a. Visualising the predictions on the test set
We first visualise the predictions from the lasso model on the test set, to obtain a sense of the overall fit compared to the actual valus
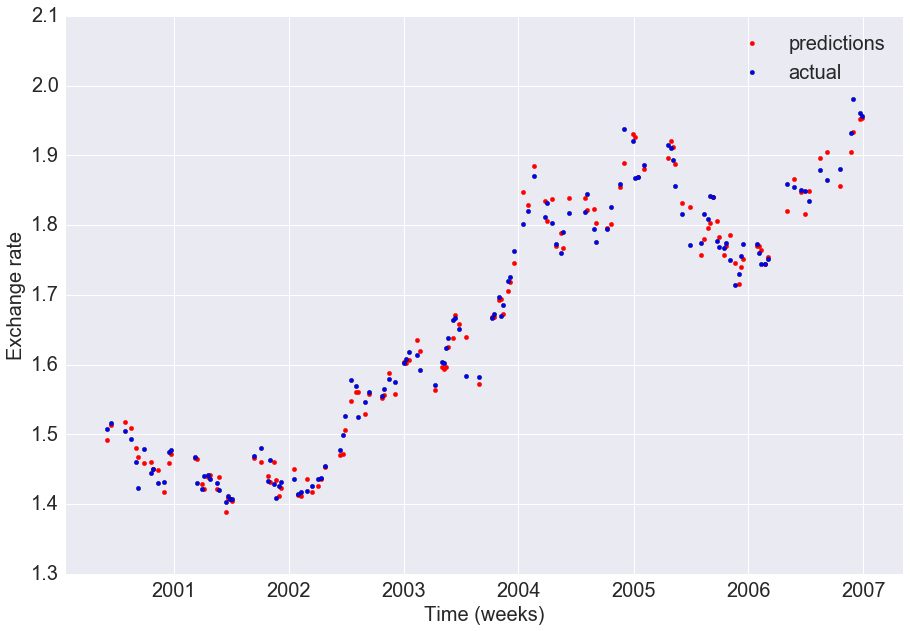
As visualised above, our predictions are close to the actual exchange rates on the test set and the R2 of the model is high (0.987)
4b. The regression coefficients of the fitted model
We can analyse which of the time lags are the most significant in our model by considering the fitted regression coefficients
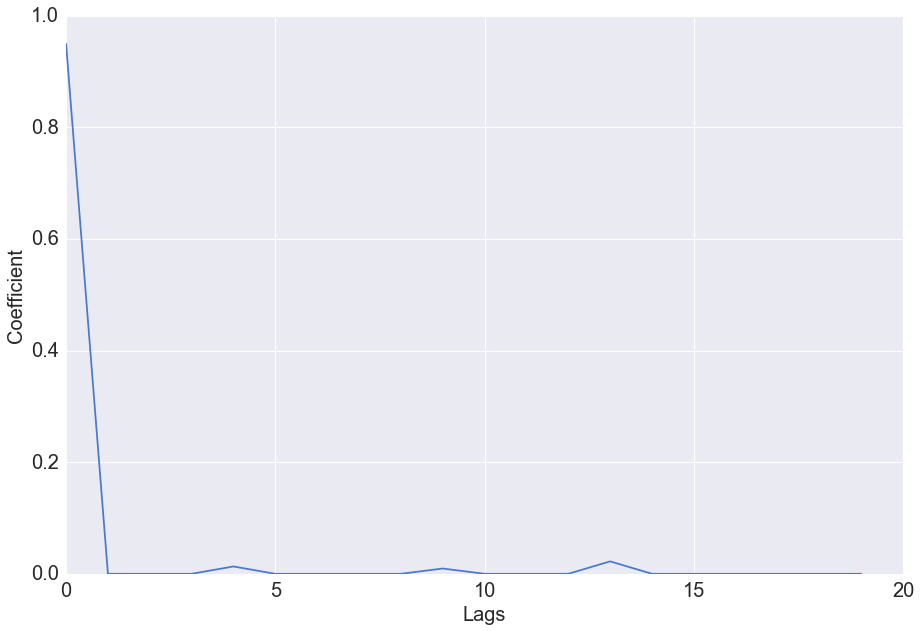
Visualisation of the coefficient values shows that beyond the first lag, the subsequent lags have little predictive value. Lasso regression squashes the predictive power of some coefficients in favour of others, and in this case has put all the predictive power in the first lag.
4c. Residual errors of the model
We can analyse the distribution of the residual errors of the model to determine if there is a predictive bias
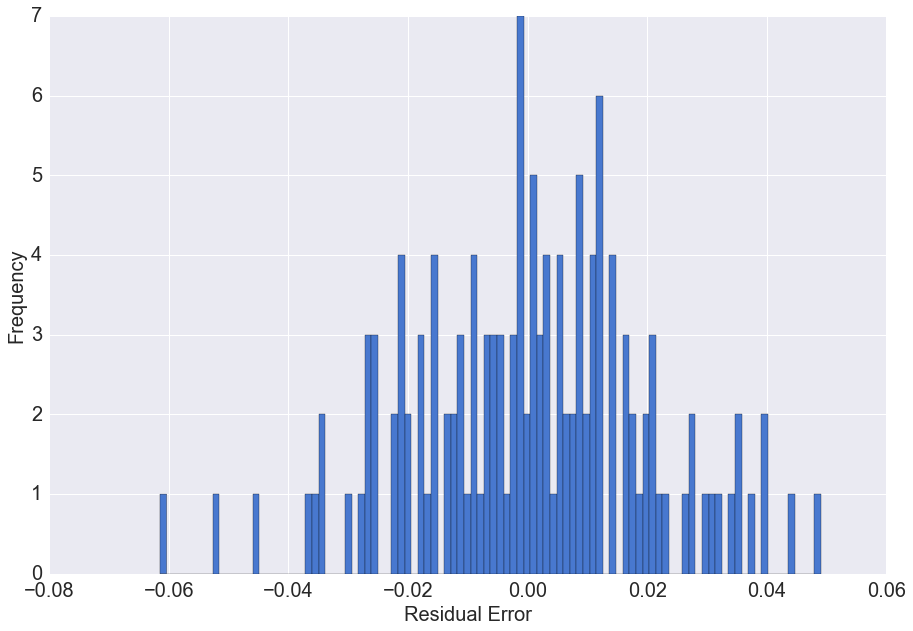
The residual errors have a distribution with mean approximately zero. This means on average our prediction model does not under or overestimate the actual values.
The univariate model is seen to have high predictive accuracy in determining the exchange rate for the following week, however forecasts further in the future are likely to have much lower accuracy (discussed later) and in these situations, the effect of news sentiment may be useful
Multivariate Lasso regression
A predictor matrix containing 20 lags of preceeding exchange rate, 20 lags of preceeding positive sentiment scores, and 20 lags of preceeding negative sentiment scores was constructed of the form
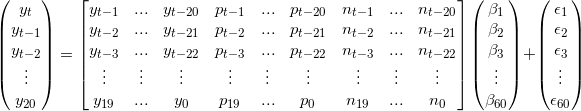
Again we can analyse which of the time lags and the positive/ negative sentiment lags are the most significant in our model, by considering the fitted regression coefficients
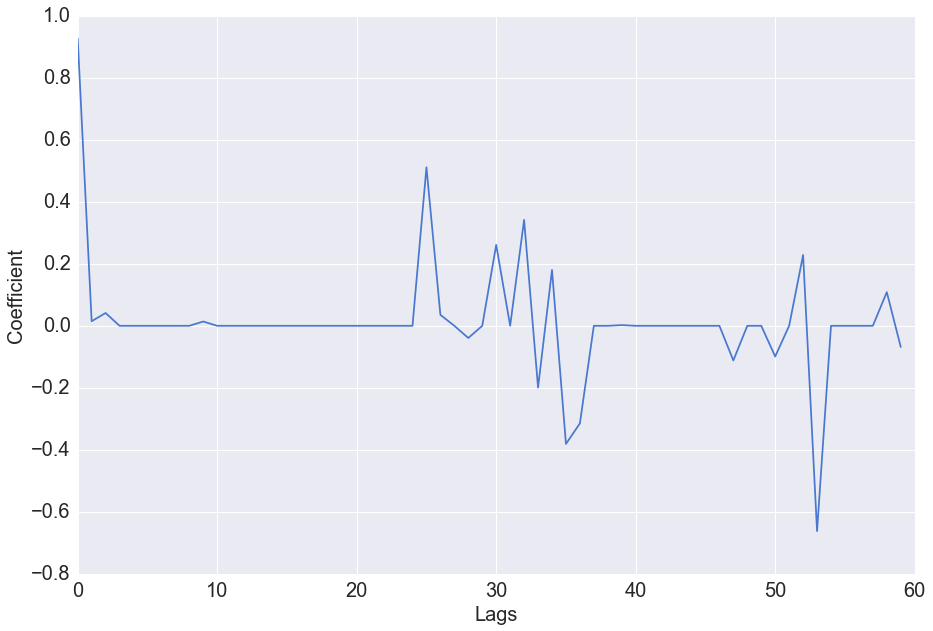
The lasso regression model has assigned high positive predictive value to the first lag as before, but the coefficients of lags of the sentiment scores are also seen to have non-zero magnitude. The positive sentiment score approximately 5 weeks prior, as well as the negative sentiment score approximately 3 weeks prior are both seen to have large coefficient values. The coefficients vary for different testing and training sets indicating that the high values for sentiment in certain weeks may be random - i.e. the important lags of sentiment are not the same over time. This will be investigated further in our future work.
Residual errors of the model
We can again analyse the distribution of the residual errors of the model
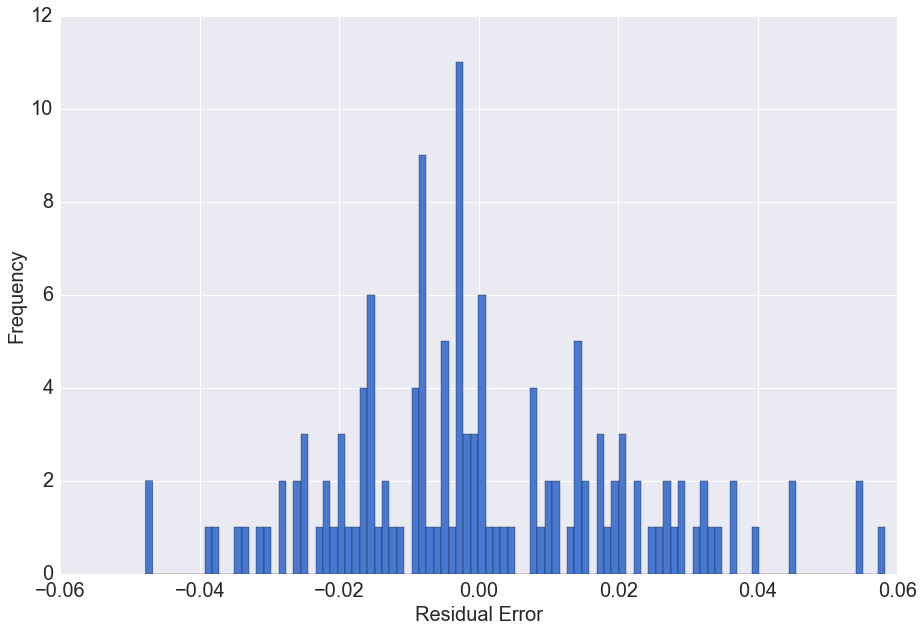
The residual errors have a distribution with mean approximately zero. This means on average our prediction model does not under or overestimate the actual values.
Model Comparison
Finally, we consider the R^2 values of the different models considered for comparison with our final foreact model which incorporates the sentiment scores.
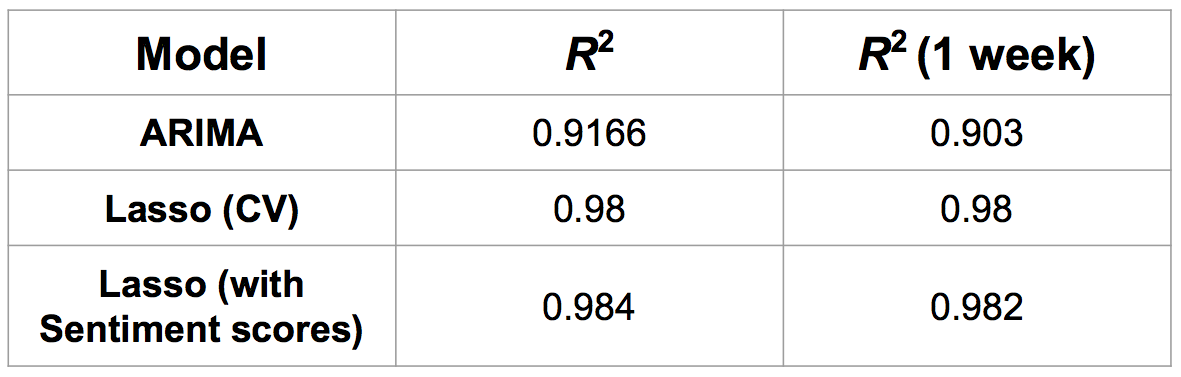
There is little increase in the predictive accuracy of the model with the incorporation of sentiment scores, showing that a simpler univariate model is in fact equally as useful as a more complex model with a larger predictor space